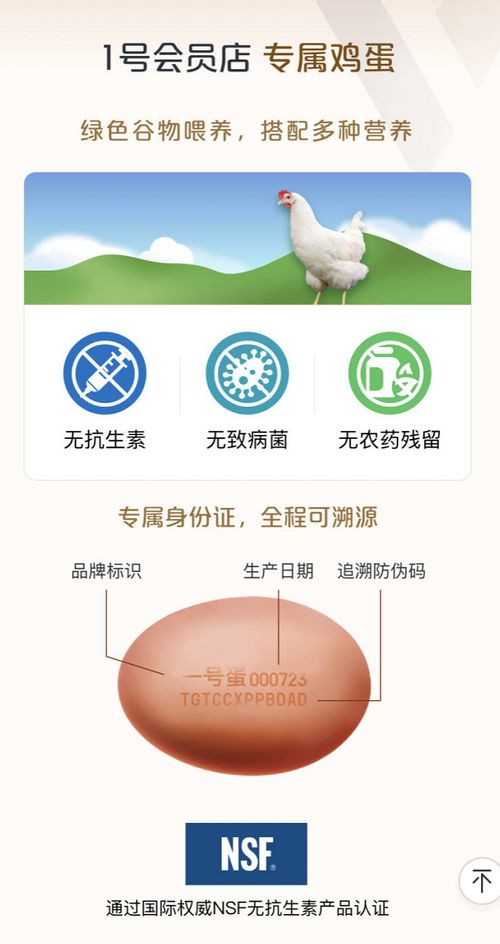
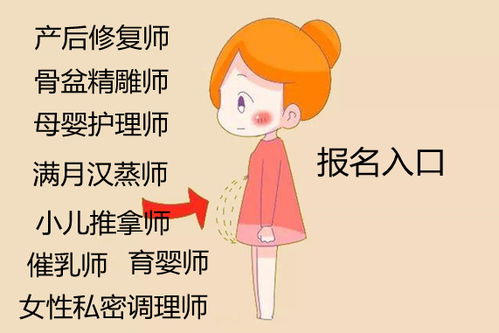
如若轉載,請注明出處:http://www.ywhetong.cn/product/14.html
更新時間:2026-04-10 11:20:03
----------------
地址:北京市豐臺區蓮花池西里11號4號樓4-5幢3層319-2室
電話:1305140**
Copyright © 2026 www.ywhetong.cn 高級催乳師 北京宏天同創科技有限公司 高級催乳師 版權所有 Sitemap